簡單的回顧的話,2006年Geoffrey Hinton的論文點燃了“這把火”,現在已經有不少人開始潑“冷水”了,主要是AI泡沫太大,而且深度學習不是包治百病的藥方。
計算機視覺不是深度學習最早看到突破的領域,真正讓大家大吃一驚的顛覆傳統方法的應用領域是語音識別,做出來的公司是微軟,而不是當時如日中天的谷歌。計算機視覺應用深度學習堪稱突破的成功點是2012年ImageNet比賽,采用的模型是CNN,而不是Hinton搞的RBM和DBN之類,就是Hinton學生做出來以他命名的AlexNet。
(注:順便提一下,2010年的ImageNet冠軍是余凱/林元慶領導的NEC和UIUC Tom Huang組的合作團隊,當時采用的方法是基于sparse coding+SVM。)
當然,真正一直在研究CNN的專家是Yann LeCun,小扎后來拉他去FB做AI research的頭。第一個CNN模型就是他搞出來的,即LeNet,原來就是做圖像數字識別。不得不說,CNN非常適合2-D信號的處理任務,RNN呢,是時域上的拓展。
現在CNN在計算機視覺應用的非常成功,傳統機器學習方法基本被棄之不用。其中最大的一個原因就是,圖像數據的特征設計,即特征描述,一直是計算機視覺頭痛的問題,在深度學習突破之前10多年,最成功的圖像特征設計
(hand crafted feature)是SIFT,還有著名的Bag of visual
words,一種VQ方法。后來大家把CNN模型和SIFT比較,發現結構還蠻像的:),之后不是也有文章說RNN和CRF很像嗎。
CNN從AlexNet之后,新模型如雨后春筍,每半年就有新發現。這里隨便列出來就是,ZFNet
(也叫MatNet),VGGNet, NIN, GoogleNet (Inception), Highway Network, ResNet,
DenseNet,SE-Net(Squeeze and Excitation Net),。。。基本上都是在ImageNet先出名的:)。
簡單回顧一下:
- AlexNet應該算第一個深度CNN;
- ZFNet采用DeconvNet和visualization技術可以監控學習過程;
- VGGNet采用小濾波器3X3去取代大濾波器5X5和7X7而降低計算復雜度;
- GoogleNet推廣NIN的思路定義Inception基本模塊(采用多尺度變換和不同大小濾波器組合,即1X1,3X3,5X5)構建模型;
- Highway Networks借鑒了RNN里面LSTM的gaiting單元;
- ResNet是革命性的工作,借鑒了Highway Networks的skip connection想法,可以訓練大深度的模型提升性能,計算復雜度變小;
- Inception-V3/4用1X7和1X5取代大濾波器5X5和7X7,1X1濾波器做之前的特征瓶頸,這樣卷積操作變成像跨通道(cross channel)的相關操作;
- DenseNet主要通過跨層鏈接解決vanishing gradient問題;
- SE-Net是針對特征選擇的設計,gating機制還是被采用;
- 前段時間流行的Attention機制也是借鑒于LSTM,實現object-aware的context模型。
在具體應用領域也出現了不少成功的模型,比如
- detection問題的R-CNN,fast RCNN,faster RCNN,SSD,YOLO,RetinaNet,CornerNet等,
- 解決segmentation問題的FCN,DeepLab,Parsenet,Segnet,Mask R-CNN,RefineNet,PSPNet,U-Net等,
- 處理激光雷達點云數據的VoxelNet,PointNet,BirdNet,LMNet,RT3D,PIXOR,YOLO3D等,
- 實現激光雷達和圖像融合的PointFusion,RoarNet,PointRCNN,AVOD等,
- 做圖像處理的DeHazeNet,SRCNN (super-resolution),DeepContour,DeepEdge等,
- 2.5 D視覺的MatchNet,DeepFlow,FlowNet等,
- 3-D重建的PoseNet,VINet,Perspective Transformer Net,SfMNet,CNN-SLAM,SurfaceNet,3D-R2N2,MVSNet等,
- 以及解決模型壓縮精簡的MobileNet,ShuffleNet,EffNet,SqueezeNet,
- 。。。
下面我們針對具體應用再仔細聊。
先說圖像/視頻處理(計算機視覺的底層,不低級)。
圖像處理,還有視頻處理,曾經是很多工業產品的基礎,現在電視,手機還有相機/攝像頭等等都離不開,是技術慢慢成熟了(傳統方法),經驗變得比較重要,而且芯片集成度越來越高,基本上再去研究的人就少了。經典的ISP,A3,都是現成的,當然做不好的也很難和別人競爭,成本都降不下來。
這是一個典型成像處理的流程圖:
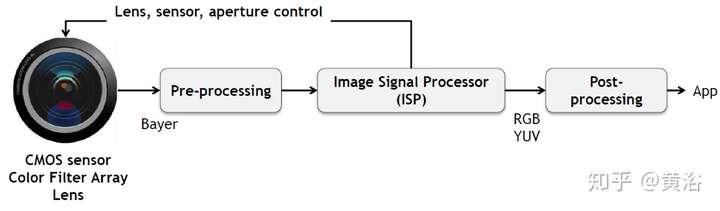
經典的ISP流程圖如下:
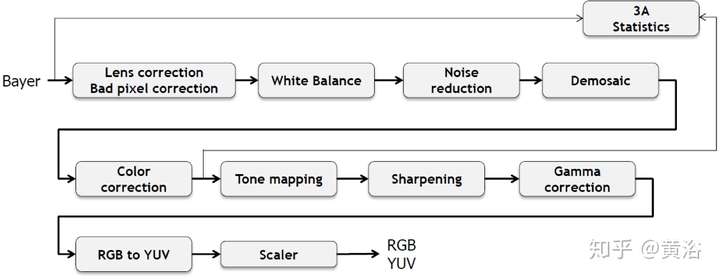
圖像處理,根本上講是基于一定假設條件下的信號重建。這個重建不是我們說的3-D重建,是指恢復信號的原始信息,比如去噪聲,內插。這本身是一個逆問題,所以沒有約束或者假設條件是無解的,比如去噪最常見的假設就是高斯噪聲,內插實際是恢復高頻信號,可以假設邊緣連續性和灰度相關性,著名的TV(total
variation)等等。
以前最成功的方法基本是信號處理,機器學習也有過,信號處理的約束條件變成了貝葉斯規則的先驗知識,比如sparse coding/dictionary learning,MRF/CRF之類,現在從傳統機器學習方法過渡到深度學習也正常吧。
1 去噪/去霧/去模糊/去鬼影;
先給出一個encoder-decoder network的AR-CNN模型(AR=Artifact Reduction):
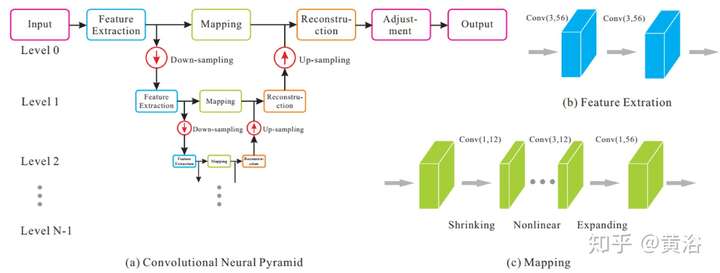
這是一個圖像處理通用型的模型框架:
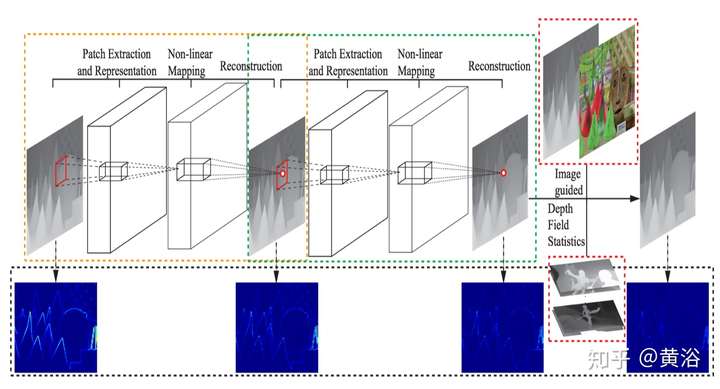
2 增強/超分辨率(SR);
Bilateral filter是很有名的圖像濾波器,這里先給出一個受此啟發的CNN模型做圖像增強的例子:
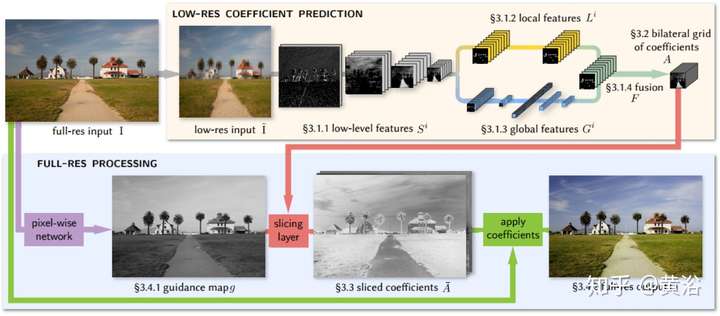
前面說過內插的目的是恢復失去的高頻信息,這里一個做SR的模型就是在學習圖像的高頻分量:
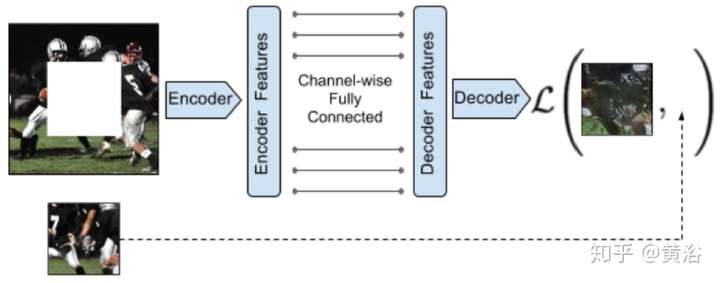
3 修補/恢復/著色;
用于修補的基于GAN思想的Encoder-Decoder Network模型:
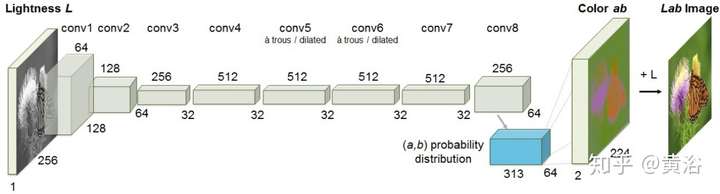
用于灰度圖像著色(8比特的灰度空間擴展到24比特的RGB空間)的模型框架:
還有計算機視覺的預處理(2-D)。
計算機視覺需要圖像預處理,比如特征提取,包括特征點,邊緣和輪廓之類。以前做跟蹤和三維重建,首先就得提取特征。特征點以前成功的就是SIFT/SURF/FAST之類,現在完全可以通過CNN形成的特征圖來定義。
邊緣和輪廓的提取是一個非常tricky的工作,細節也許就會被過強的圖像線條掩蓋,紋理(texture)本身就是一種很弱的邊緣分布模式,分級(hierarchical)表示是常用的方法,俗稱尺度空間(scale
space)。以前做移動端的視覺平臺,有時候不得不把一些圖像處理功能關掉,原因是造成了特征畸變。現在CNN這種天然的特征描述機制,給圖像預處理提供了不錯的工具,它能將圖像處理和視覺預處理合二為一。
1 特征提取;
LIFT(Learned Invariant Feature Transform)模型,就是在模仿SIFT:
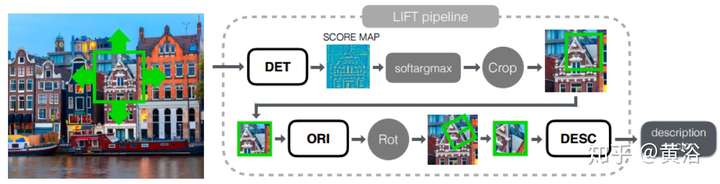
2 邊緣/輪廓提取;
一個輪廓檢測的encoder-decoder network模型:
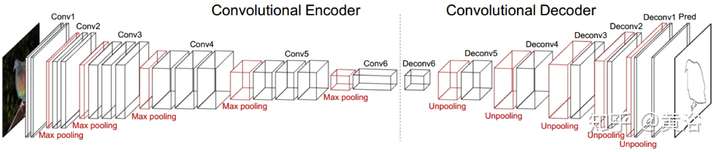
3 特征匹配;
這里給出一個做匹配的模型MatchNet:
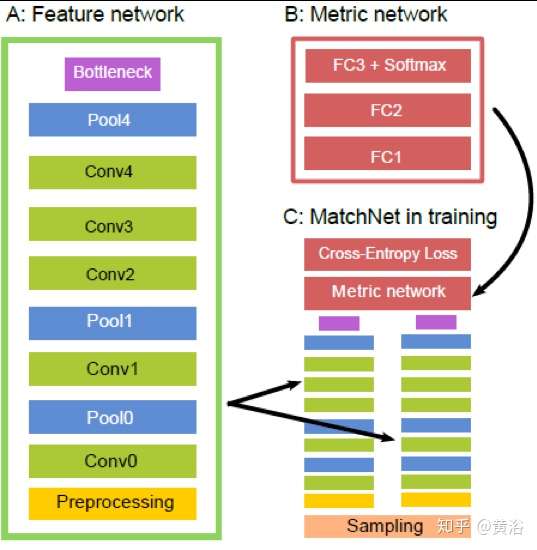
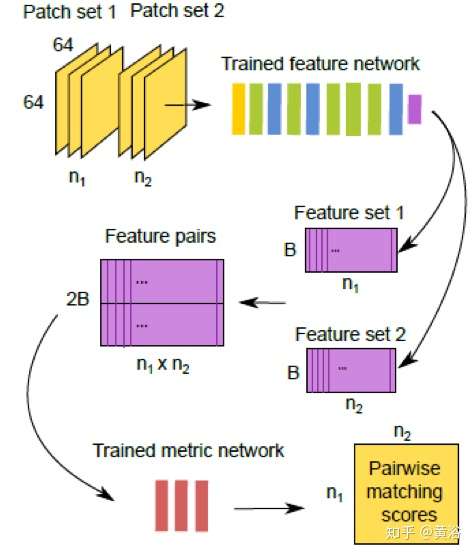
再說2.5-D計算機視覺部分(不是全3-D)。
涉及到視差或者2-D運動的部分一般稱為2.5-D空間。這個部分和前面的2-D問題是一樣的,作為重建任務它也是逆問題,需要約束條件求解優化解,比如TV,GraphCut。一段時間(特別是Marr時代)計算機視覺的工作,就是解決約束條件下的優化問題。
后來,隨機概率和貝葉斯估計大行其事,約束條件變成了先驗知識(prior),計算機視覺圈里寫文章要是沒有
P (Probability) 和 B (Bayes),都不好意思發。像SVM, Boosting,Graphical
Model,Random Forest,BP(Belief Propagation),CRF(Conditional Random
Field),Mixture of Gaussians,MCMC,Sparse Coding都曾經是計算機視覺的寵兒,現在輪到CNN出彩:)。
可以說深度學習是相當“暴力”的,以前分析的什么約束呀,先驗知識呀在這里統統扔一邊,只要有圖像數據就可以和傳統機器學習方法拼一把。
1 運動/光流估計;
傳統的方法包括局部法和全局法,這里CNN取代的就是全局法。
這里是一個光流估計的模型:
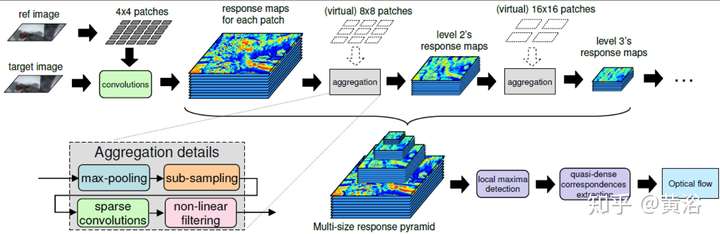
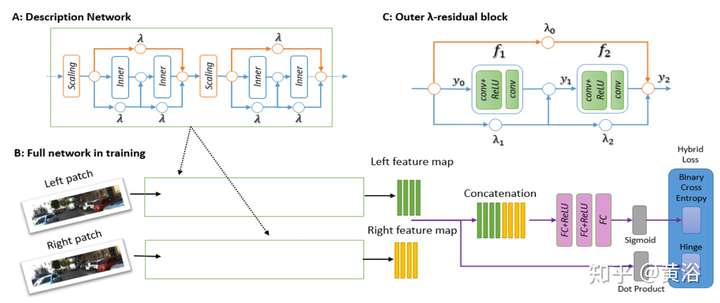
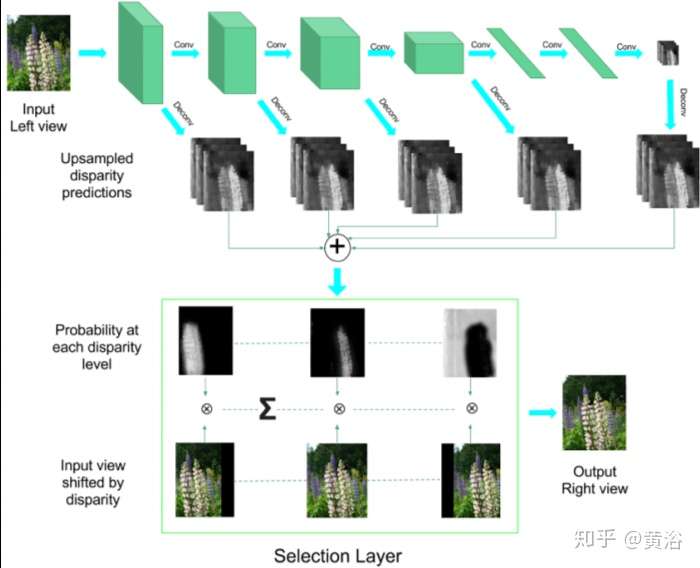
2 視差/深度圖估計;
深度圖估計和運動估計是類似問題,唯一不同的是單目可以估計深度圖,而運動不行。
這里是一個雙目估計深度圖的模型:
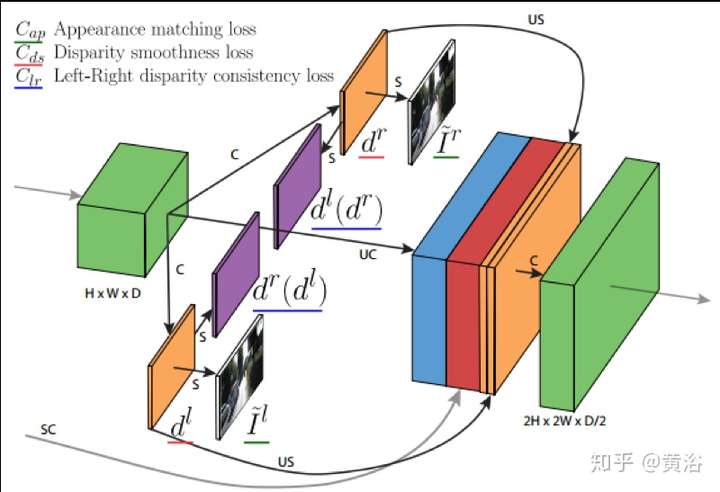
而這個是單目估計深度圖的模型:巧妙的是這里利用雙目數據做深度圖估計的非監督學習
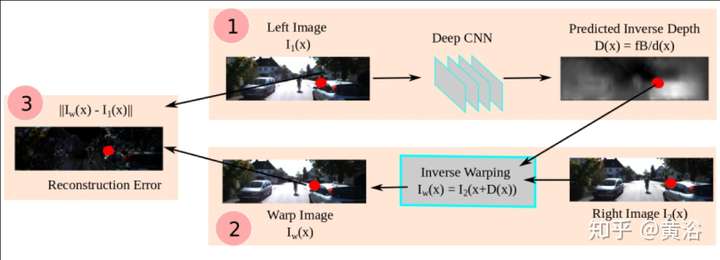
另外一個單目深度估計的模型:也是利用雙目的幾何約束做非監督的學習
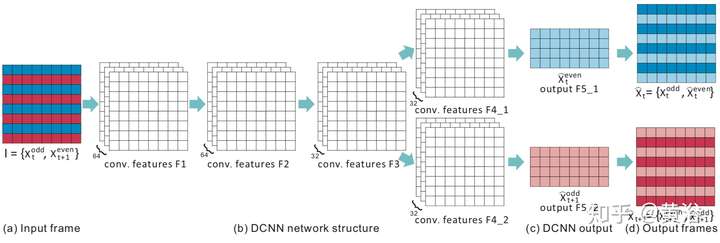
3 視頻去隔行/內插幀;
Deinterlacing和Framerate upconversion視頻處理的經典問題,當年Sony和Samsung這些電視生產商這方面下了很大功夫,著名的NXP(從Philips公司spin-off)當年有個牛逼的算法在這個模塊掙了不少錢。
基本傳統方法都是采用運動估計和補償的方法,俗稱MEMC,所以我把它歸類為2.5-D。前面運動估計已經用深度學習求解了,現在這兩個問題自然也是。
首先看一個做MEMC的模型:
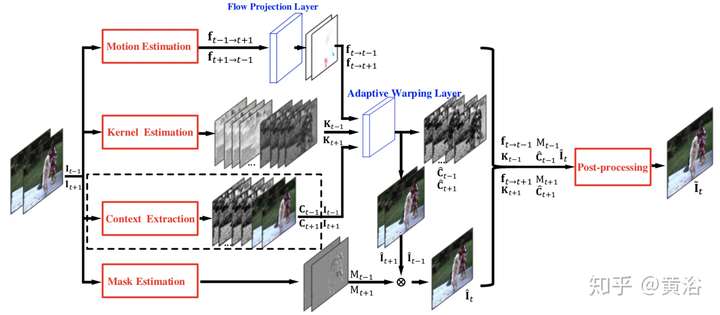
這是做Deinterlacing的一個模型:
這是Nvidia的Framerate Upconversion方面模型:
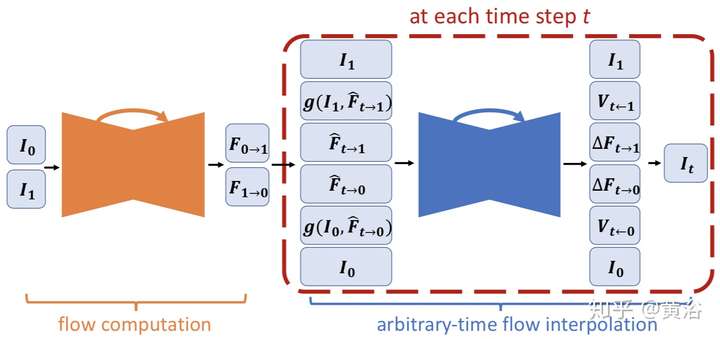
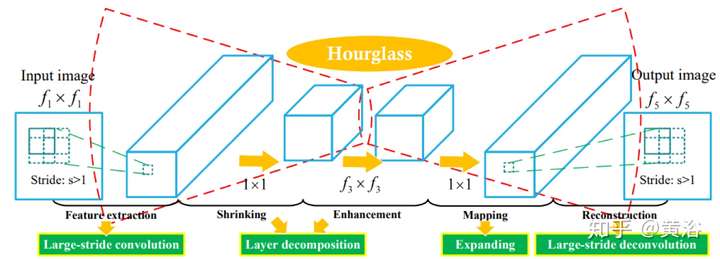
因為它采用optic flow方法做插幀,另外附上它的flow estimation模型:就是一個沙漏(hourglass)模式
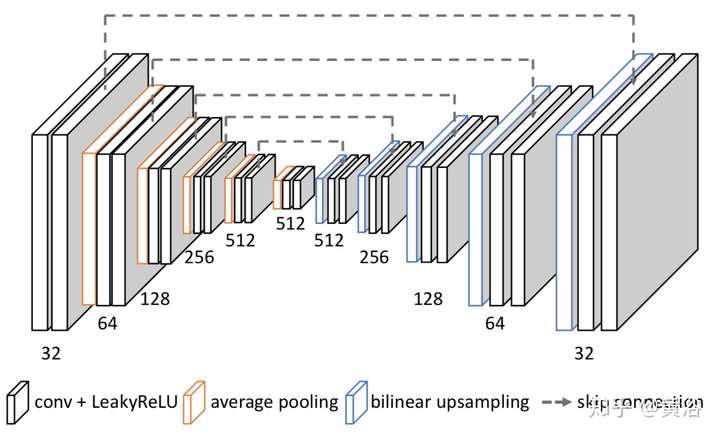
4 新視角圖像生成;
剛才介紹單目估計深度圖的時候,其實已經看到采用inverse warping方法做新視角生成的例子,在IBR領域這里有一個分支叫Depth Image-based Rendering (DIBR)。
和上個問題類似,采用深度圖學習做合成圖像,也屬于2.5-D空間。在電視領域,曾經在3-D電視界采用這種方法自動從單鏡頭視頻生成立體鏡頭節目。以前也用過機器學習,YouTube當年采用image
search方法做深度圖預測提供2D-3D的內容服務,但性能不好。現在感覺,大家好像不太熱衷這個了。
這是一個產生新視角的模型:
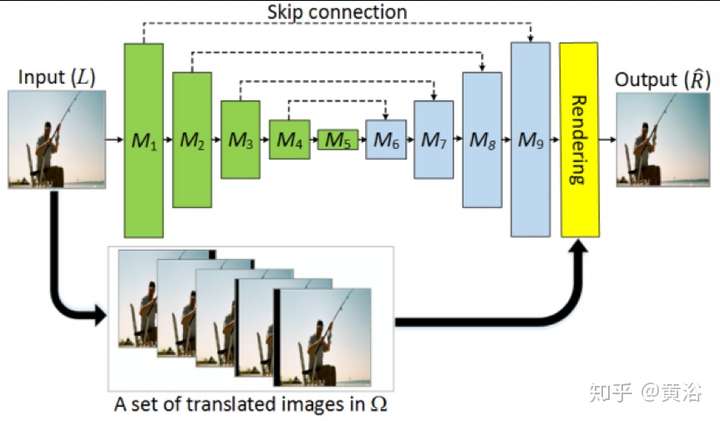
而這個是從單鏡頭視頻生成立體視頻的模型:
有做編碼/解碼的,也是采用運動或者相似變換為基礎,但性能不如傳統方法,這里忽略。
下面談談3-D,基于多視角(MVS)/運動(SFM)的重建,后者也叫SLAM。
這部分就是經典的計算機視覺問題:3-D重建。
基本上可以分成兩種路徑:一是多視角重建,二是運動重建。前一個有一個經典的方法MVS(multiple
view
stereo),就是多幀匹配,是雙目匹配的推廣,這樣采用CNN來解決也合理。當年CMU在Superbowl展示的三維重建和視角轉化,轟動一時,就是基于此路徑,但最終沒有被產品化(技術已經轉讓了)。
后一個在機器人領域成為SLAM,有濾波法和關鍵幀法兩種,后者精度高,在稀疏特征點的基礎上可以采用BA(Bundle
Adjustment),著名的方法如PTAM,ORB-SLAM1/2,LSD-SLAM,KinectFusion(RGB-D),LOAM和Velodyne
SLAM(LiDAR)等。如今SLAM已經成為AR產業的瓶頸,看看MagicLeap和HoloLens,大家不能總是在平面檢測基礎上安一個虛擬物體吧,真正的虛實結合是在一個普通的真實環境里才行。
想想像特征點匹配,幀間運動估計,Loop Closure檢測這些模塊都可以采用CNN模型解決,那么SLAM/SFM/VO就進入CNN的探索區域。
1 標定;
Calibration是計算機視覺的經典問題,攝像頭作為傳感器的視覺系統首要任務就是要確定自己觀測數據和3-D世界坐標系的關系,即標定。攝像頭標定要確定兩部分參數,一是內參數,二是外參數。對于有多個傳感器的視覺系統,比如深度測距儀,以前有Kinect
RGB-D,現在有Velodyne激光雷達,它們相互之間的坐標系關系是標定的任務。
外參數標定的完成幫助是校準數據,比如激光雷達的點云,RGB-D的深度圖,還有攝像頭的圖像像素集,它們一定存在一個最佳匹配標準,這就可以通過數據訓練NN模型來完成。而標定參數就是NN模型回歸輸出的結果。
這里是一個激光雷達和攝像頭標定的系統框圖:
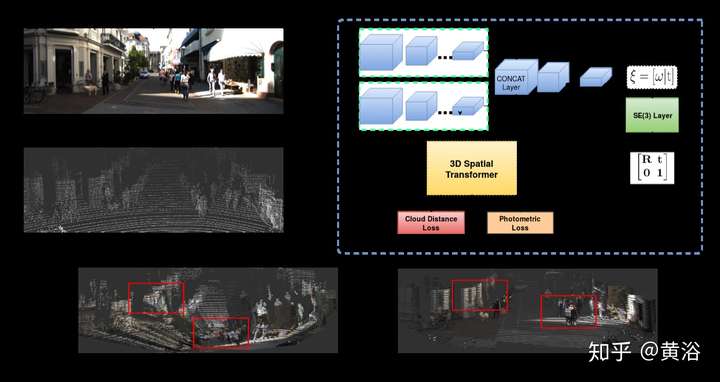
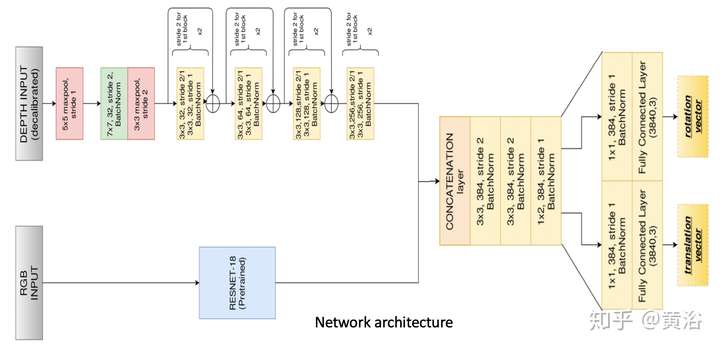
它的模型CalibNet結構視圖:
2 Visual Odometry(VO);
VO屬于SLAM的一部分,只是估計自身運動和姿態變化吧。VO是特斯拉的前Autopilot2.0負責人David Nister創立的,他之前以兩幀圖像計算Essential Matrix的“5點算法”而出名,現在是Nvidia的自動駕駛負責人,公司VP。
這里是一個和慣導數據結合的VIO(Visual-Inertial Odometry)NN模型:
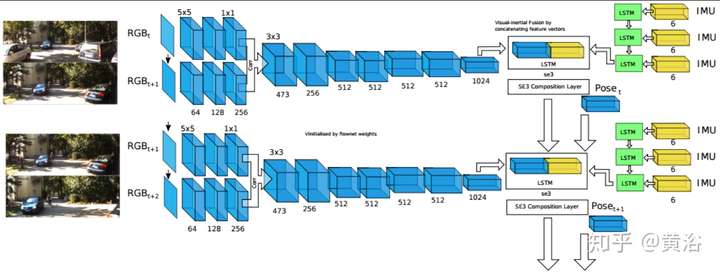
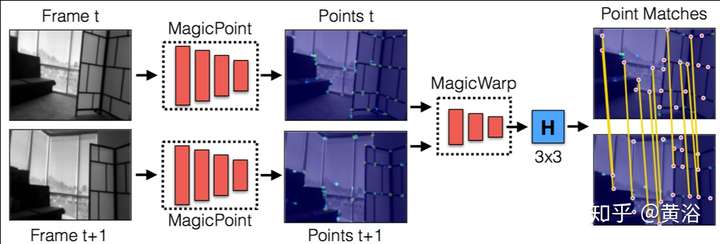
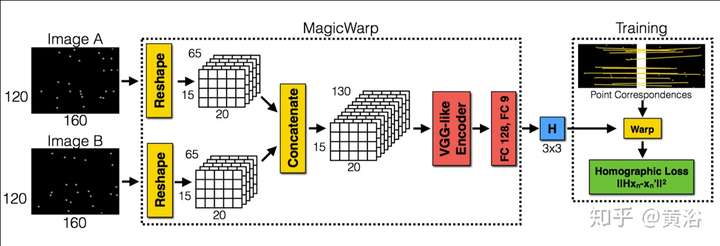
這是著名的AR創業公司MagicLeap提出的VO模型:兩部分組成,即特征提取和匹配(Homography)。

順便加一個,激光雷達數據做Odometry的CNN模型:
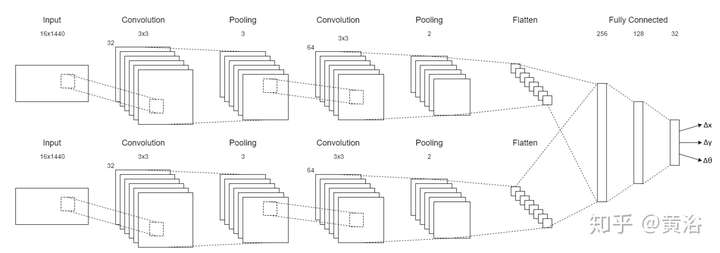
3 SLAM (Mono, Stereo, RGB-D, LiDAR)/SFM;
運動恢復結構是基于背景不動的前提,計算機視覺的同行喜歡SFM這個術語,而機器人的peers稱之為SLAM。SLAM比較看重工程化的解決方案,SFM理論上貢獻大。
先看一個單攝像頭的SFM系統框圖:
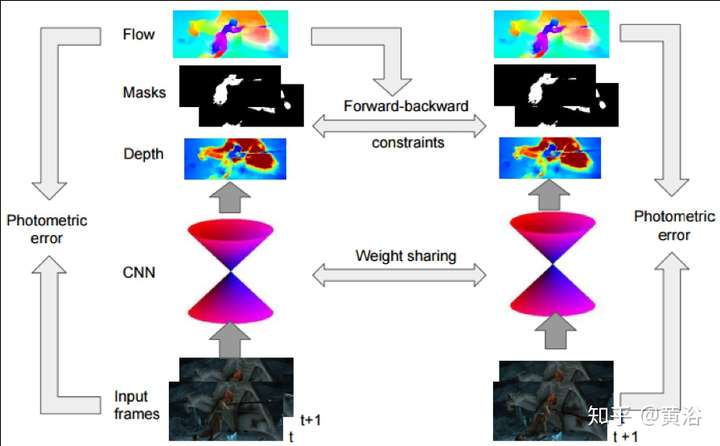
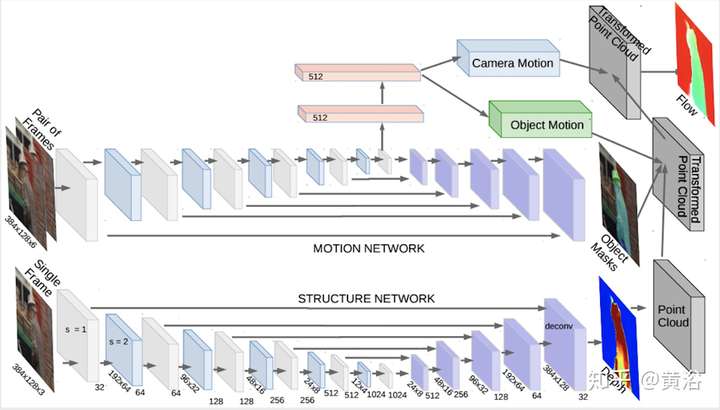
它的NN模型SFM-Net,包括Motion和Structure兩部分:
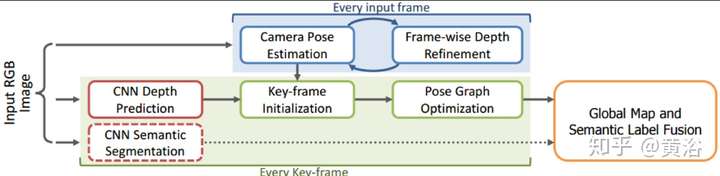
再附上一個SLAM的模型CNN-SLAM:主要是加上一個單目深度圖估計的CNN模塊。
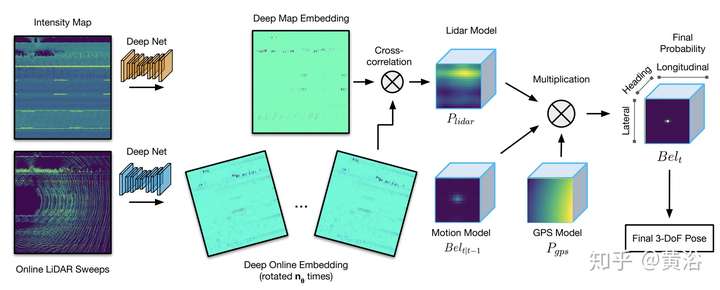
這是一個用CNN的基于Lidar的localization方法:不僅需要點云數據,還輸入反射值灰度圖。
圖像像素運動是optic flow,而3-D場景的運動稱之為scene flow,如果有激光雷達的點云數據,后者的估計可以通過ICP實現,這里給出一個CNN模型的實現方法FlowNet3D,是PointNet的擴展:
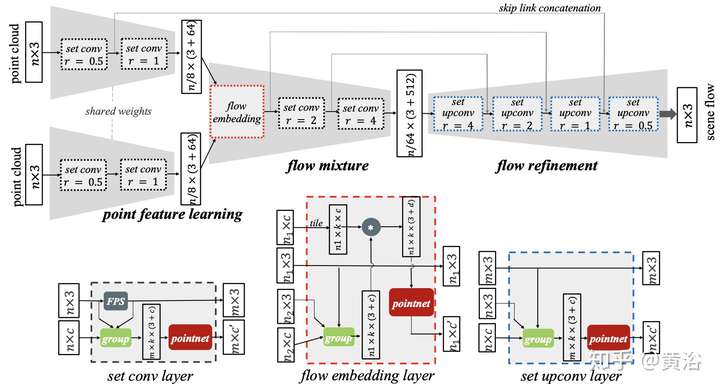
4 MVS;
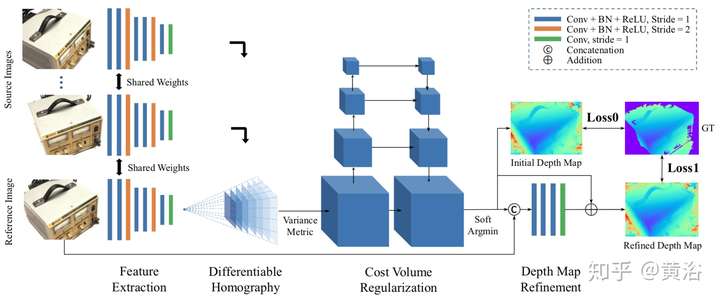
MVS的傳統方法可以分成兩種:region growing和depth-fusion,前者有著名的PMVS,后者有KinectFusion,CNN模型求解MVS的方法就是基于此。
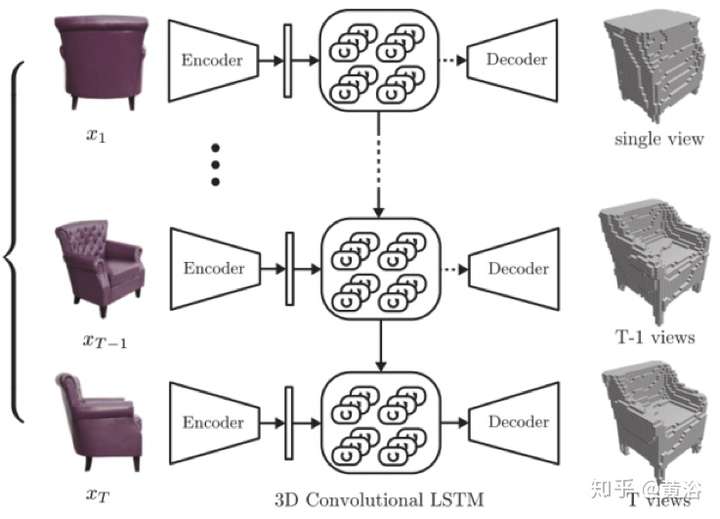
先看看一個做MVS任務的基于RNN中LSTM的3D-R2N2模型:
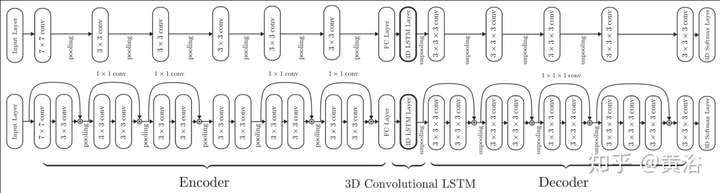
它的系統框圖如下:
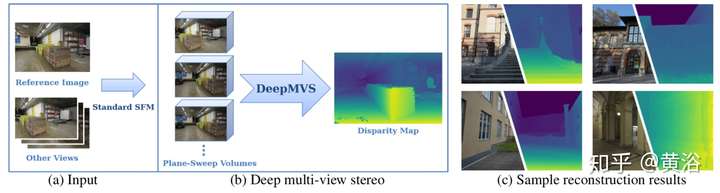
UIUC/Facebook合作的DeepMVS模型:
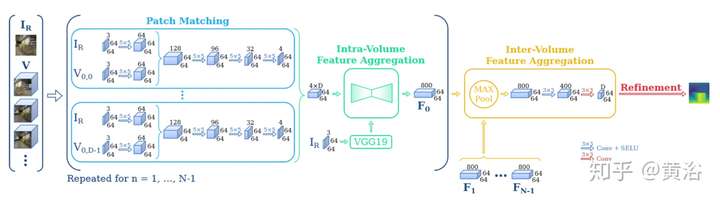
這是他們的系統框圖:
現在看到的是Berkeley分校Malik組提出的LSM(Learnt Stereo Machine )模型:
下面是最近香港權龍教授組提出的MVSNet模型:
核心部分是計算機視覺的高層:環境理解。
這部分是深度學習在計算機視覺最先觸及,并展示強大實力的部分。出色的工作太多,是大家關注和追捧的,而且有不少分析和總結文章,所以這里不會重復過多,只簡單回顧一下。
1 語義分割/實例分割(Semantic/Instance Segmentation);
語義分割最早成功應用CNN的模型應該是FCN(Fully Convolution Network),由Berkeley分校的研究人員提出。它是一種pixel2pixel的學習方法,之后各種演變模型,現在都可以把它們歸類于Encoder-Decoder Network。
這里是去年CVPR的一片論文在總結自動駕駛的實時語義分割算法時給出的框圖:
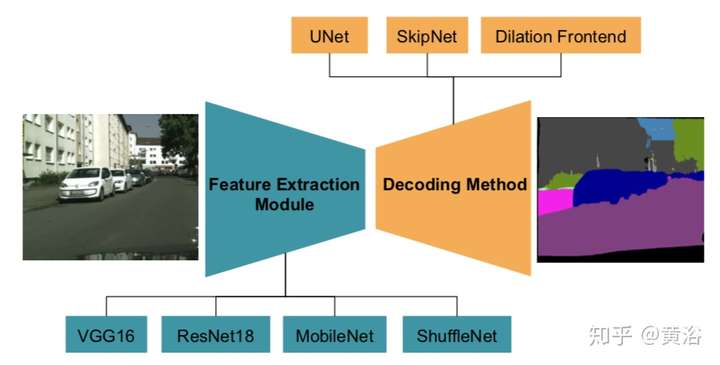
其中Encoder部分特別采用了MobileNet和ShuffleNet。
實例分割是特殊的語義分割,結合了目標檢測,可以說是帶有明確輪廓的目標檢測,其代表作就是Mask R-CNN,應該是何凱明去FB之后的第一個杰作。
這是一個借鑒目標檢測算法SSD的實例分割模型:
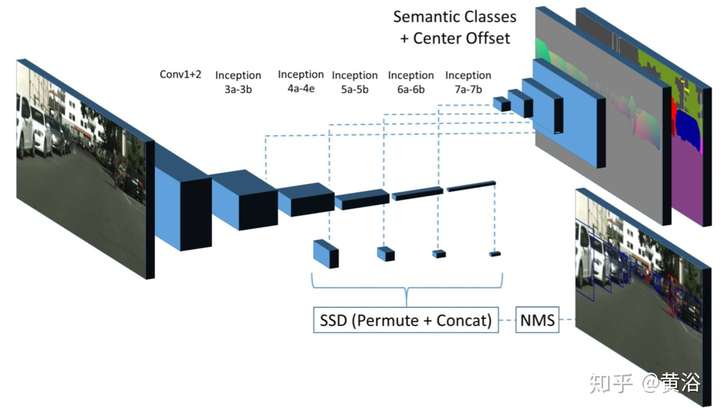
而下面這個是從目標檢測算法Faster-RCNN演變的實例分割模型MaskLab,論文發表在去年CVPR‘18:
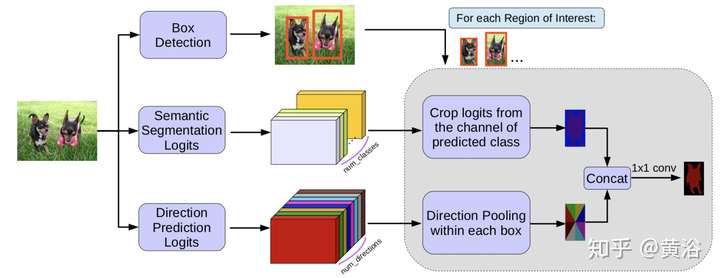
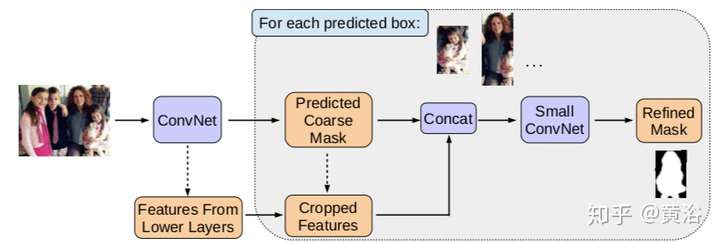
這是它修正Mask的方法示意圖:
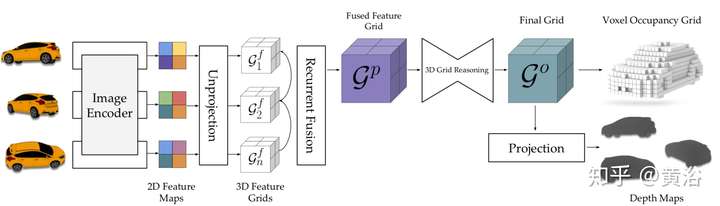
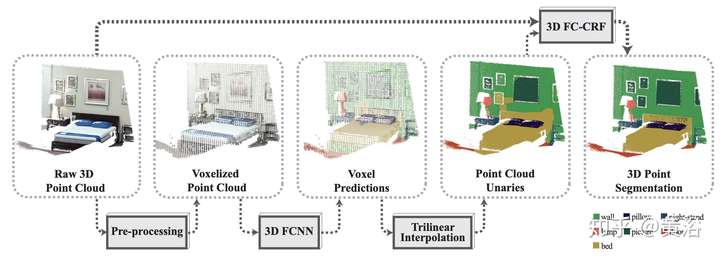
這是一個基于3-D點云的語義分割NN模型:
2 檢測/識別(特別例子:人臉);
目標檢測的開拓性工作應該是Berkeley分校Malik組出來的,即兩步法的R-CNN(Region-based
CNN),借用了傳統方法中的Region Proposal。之后不斷改進的有fast RCNN和faster
RCNN,每次都有新點子,真是“群星閃耀”的感覺。
一步法的工作,有名的就是SSD(Single Shot
Detection)和YOLO(You Only Look
Once),期間何凱明針對one-stage和two-stage方法的各自優缺點引進一個Focal
Loss,構建的新方法叫RetinaNet,而后來YOLO3基本也解決了精度低的弱點。
這里我畫了一個算法發展草圖(其實還有一些方法沒有包括在里面,比如densebox,deepbox,R-FCN,FPN等等)。
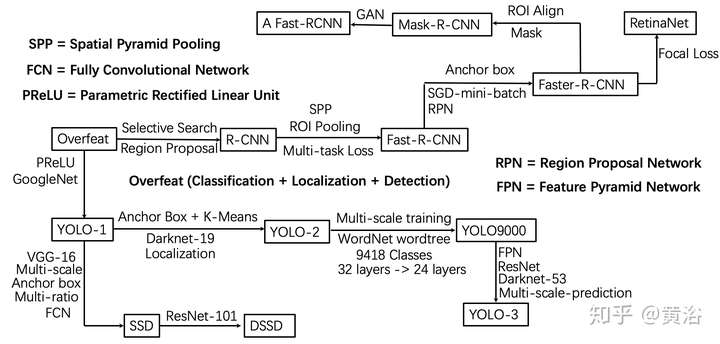
ImageNet本身就是一個1000多種物體識別比賽,一般公布的是top 5的結果(可見最早精度有多低(:)。CNN在ImageNet的發展史,就是它在圖像識別的一段近5年的歷史了:)。
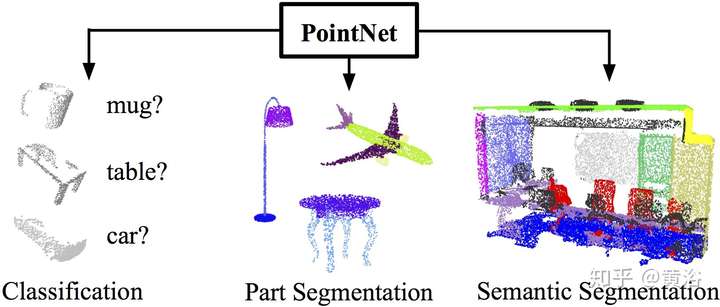
激光雷達點云數據的處理,無論識別還是分割,有PointNet以及改進的CNN模型:
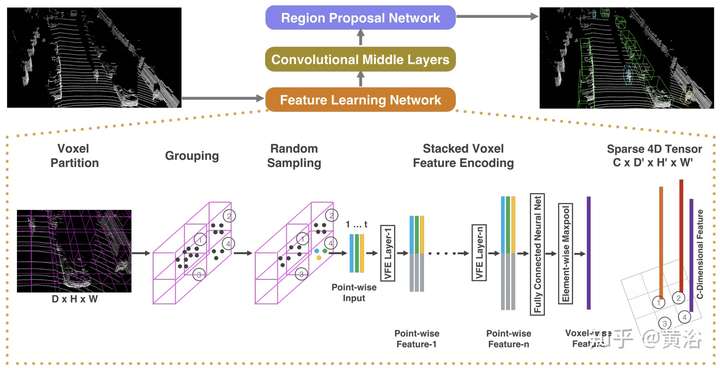
基于點云做目標識別的例子有Apple公司研究人員發表的VoxelNet模型:
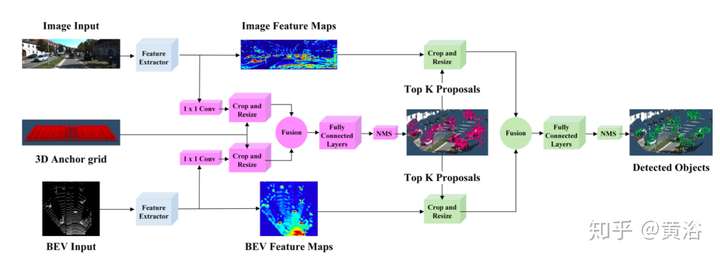
將點云和RGB圖像結合的目標檢測CNN模型例子如下:
這里順便提一下人臉識別,因為是對人臉的個體屬性判別,所以這個課題應該算fine grained recognition。就好像對狗或者馬這種動物繼續判別它的品種,都是細分的。
請注意,人臉識別分人臉驗證(face
verification)和人臉確認(face identification);前者是指兩個人是不是同一個人,1-to-1
mapping,而后者是確定一個人是一群人中的某個,1-to-many
ampping。以前經常有報道機器的人臉識別比人強了,都是指前者,假如后者的話,那誰能像機器一樣識別上萬人的人臉數據庫呢?何況中國公安部的數據高達億的數量級。
一個完整的人臉識別系統,需要完成人臉檢測和人臉校準(face alignment),而后者是需要人臉關鍵點(facial landmarks)的檢測,也是可以基于CNN模型來做。這里以FB的DeepFace模型為例吧,給出一個人臉識別的系統框圖:

這是不久前剛剛提出的人臉檢測模型: Selective Refinement Network
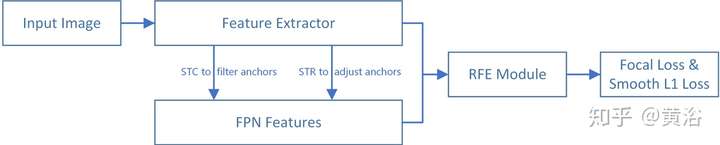
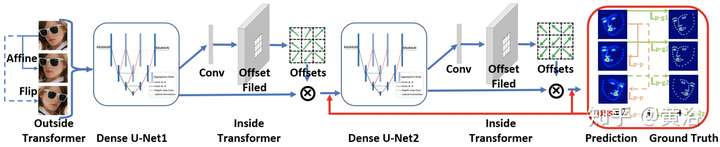
而這里給出一個基于facial landmarks做校準的模型:
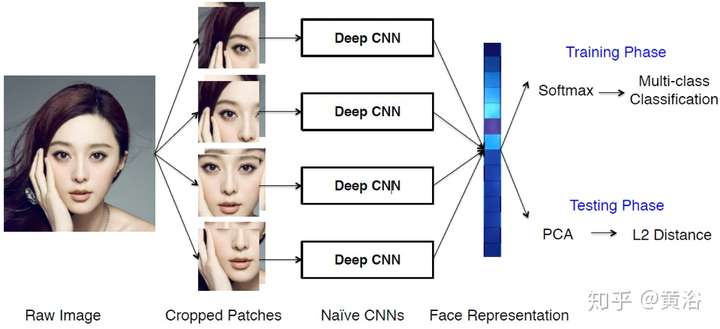
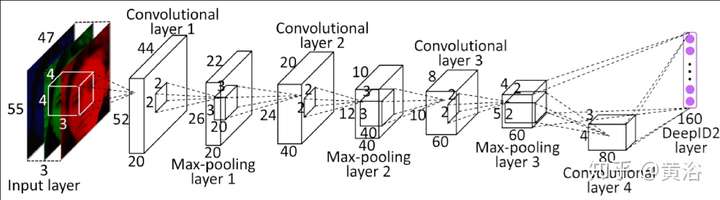
順便提一下曠世科技的Pyramid CNN模型和商湯科技的DeepID2模型(一共發布過4個DeepID版本)依次如圖:
3 跟蹤(特別例子:人體姿態/骨架);
目標跟蹤是一個遞推估計問題,根據以前的圖像幀目標的信息推算當前目標的位置甚至大小/姿態。有一陣子,跟蹤和檢測變得渾為一體,即所謂tracking by detection,跟蹤也可以看出一個目標分割(前后景而言)/識別問題。
跟蹤是短時(short
term)鄰域的檢測,而一般的檢測是長時(long
term)大范圍的檢測。跟蹤的困難在于目標的遮擋(分部分還是全部),背景復雜(相似目標存在),快速(fast)以及突變(agile)運動等等。比如,跟蹤人臉,當轉90度成側臉時就會有以上這些問題。
跟蹤方法有一個需要區分的點,多目標(MOT)還是單目標(SOT)跟蹤器。單目標不會考慮目標之間的干擾和耦合,而多目標跟蹤會考慮目標的出現,消失以及相互交互和制約,保證跟蹤各個目標的唯一性是算法設計的前提。
跟蹤目標是多樣的,一般是考慮剛體還是柔體,是考慮單剛體還是鉸接式(articulated),比如人體或者手指運動,需要確定skeleton模型。跟蹤可以是基于圖像的,或者激光雷達點云的,前者還要考慮目標在圖像中大小的變化,姿態的變化,難度更大。
基于以上特點,跟蹤可以用CNN或者RNN模型求解,跟蹤目標的描述本身就是NN模型的優勢,檢測也罷,分割或者識別也罷,都不是問題。運動特性的描述也可以借鑒RNN模型,不過目前看到的結果這部分不比傳統方法好多少。
先看一個單目標跟蹤的CNN模型:
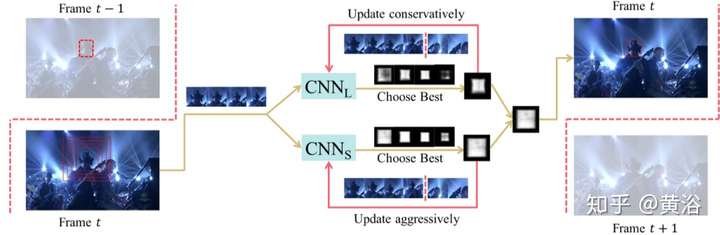
這個展示的模型是一個基于R-CNN檢測模型擴展的單目標跟蹤方法:
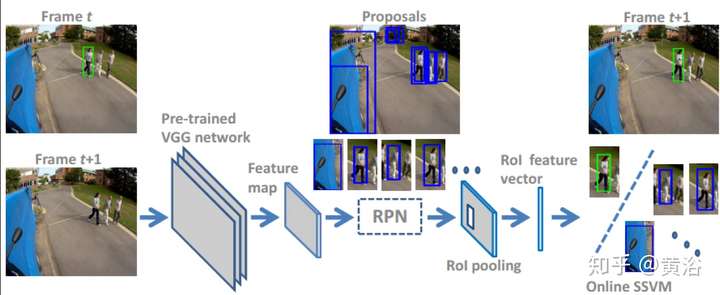
多目標跟蹤模型有這么一個例子:
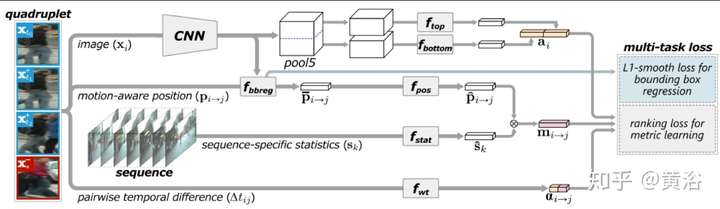
下面是一個基于RNN的多目標跟蹤模型:
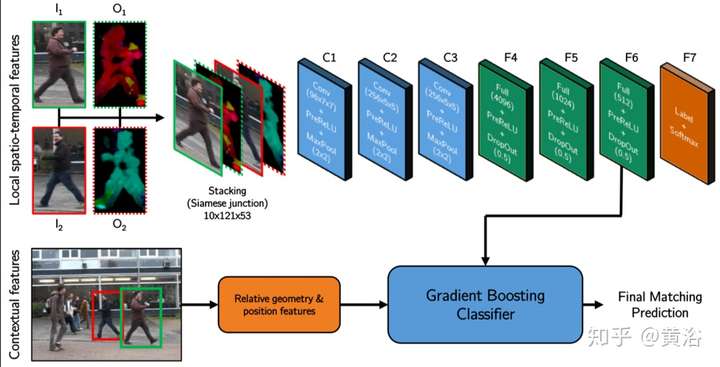
補充一個基于RGB圖像和3-D點云的目標跟蹤NN模型:
順便談一下人體姿態和骨架跟蹤問題。以前傳統方法在人體姿態估計花了很大力氣但效果不好,提出了part-based目標模型,比如constellation
model, pictorial structure, implicit shape model, deformable model等等。
最近CMU提出一個方法,基于Part
Affinity
Fields(PAF)來估計人體姿態和骨架,速度非常快。PAF是一個非參數描述模型,用來將圖像像素和人體各肢體相關起來,看它的架構如圖,采用的是two
branch CNN結構,聯合學習各肢體的相關性和位置。
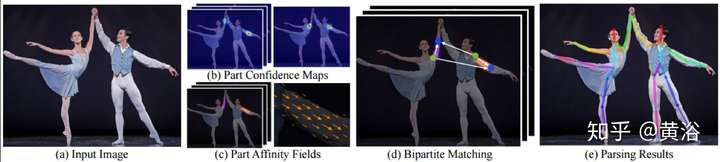
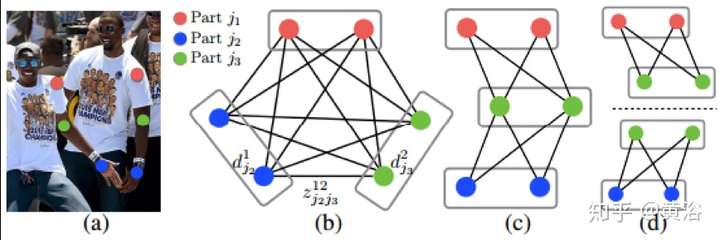
下面這個是其中雙部圖形匹配(Bipartie matching)算法的示意圖。
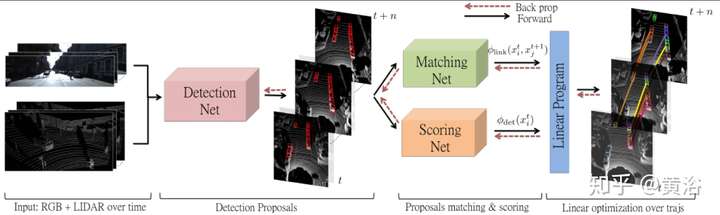
這種多目標快速姿態跟蹤的實現對人體行為的理解是非常重要的工具。
最后講一下計算機視覺的推廣領域。
這里我選了4個計算機視覺的應用談談深度學習對這些領域的推動,在CNN或者RNN“火”之前,這些應用已經存在,但在識別分類任務上性能有限罷了。自動駕駛的應用在另外文章已經提過了,在此忽略。
1 內容檢索;
CBIR(Content-based
Image
Retrieval)有兩波人搞,一波是計算機科學的,把這個問題當數據庫看待;另一波人是電子過程的,認為是圖像匹配問題。剛開始大家也是對這個問題的semantic
gap比較頭疼,用了一些feature,比如顏色,紋理,輪廓,甚至layout,效果真不咋樣。
后來有了SIFT,用了Information
Retrieval的概念Bag of Words,加上inverted Indexing,TF-IDF(term
frequency–inverse document frequency),hashing之類的技術變得好多了,每年ACM
MM會議上一堆的paper。深度學習進來,主要就是扮演特征描述的角色。
這是一個CBIR采用CNN的框架:
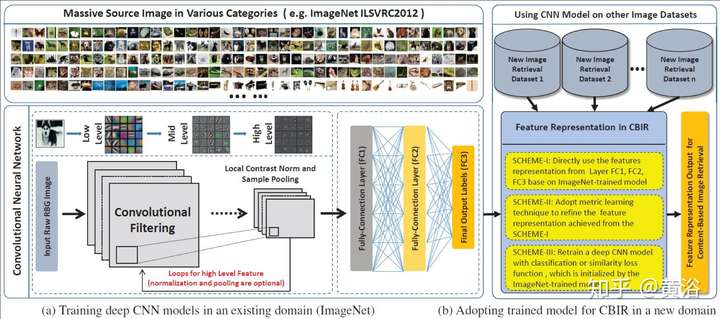
這個展示的是image matching用于CBIR的CNN模型:
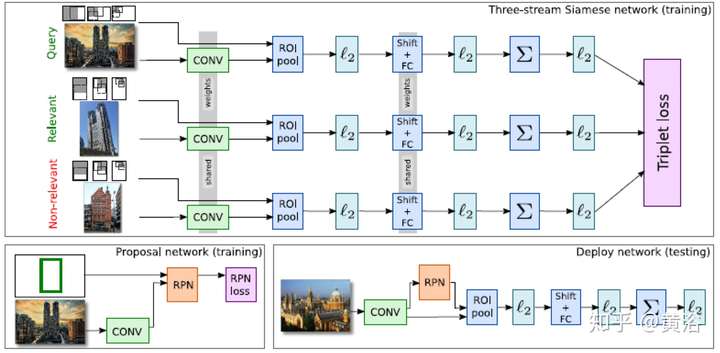
2 增強現實;
AR一開始就不好做,不說VR那部分的問題,主要是實時性要求高,無論識別還是運動/姿態估計,精度都不好。現在計算機硬件發展了,計算速度提高了,加上深度學習讓識別變得落地容易了,最近越來越熱,無論是姿態估計還是特征匹配(定位),都變得容易些了。希望這次能真正對社會帶來沖擊,把那些AR的夢想都實現。
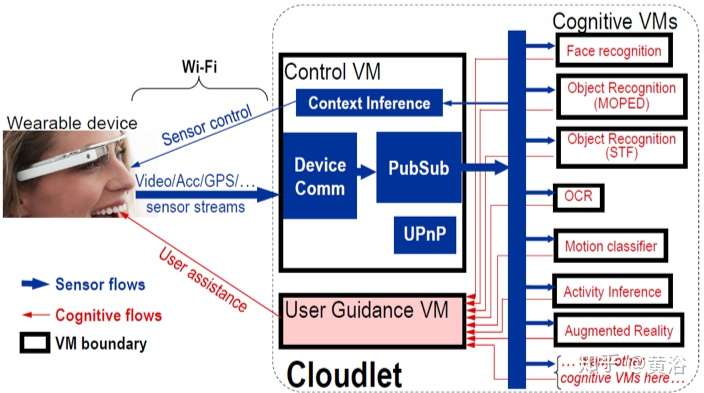
這個框架是Google Glass的AR應用平臺,其中幾個模塊都可以基于CNN實現:
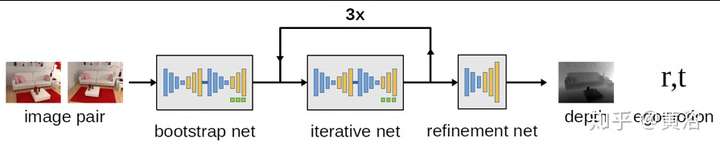
下面給出的是camera motion 的encoder-decoder network框架:三個模型串聯,其中一個有迭代。
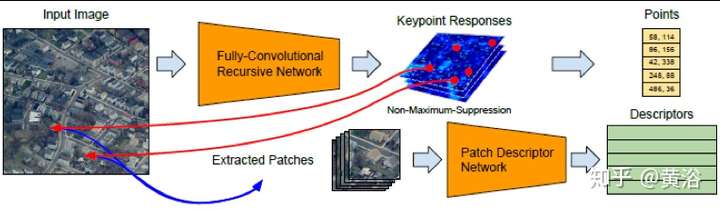
下面的模型展示了特征提取和描述的作用,AR中直接可以用做re-localization。
3 內容加注/描述;
Captioning是計算機視覺和NLP的結合。你可以把它當成一個“檢索”任務,也可以說是一個“翻譯”工作。深度學習,就是來幫助建立一個語言模型并取樣產生描述。
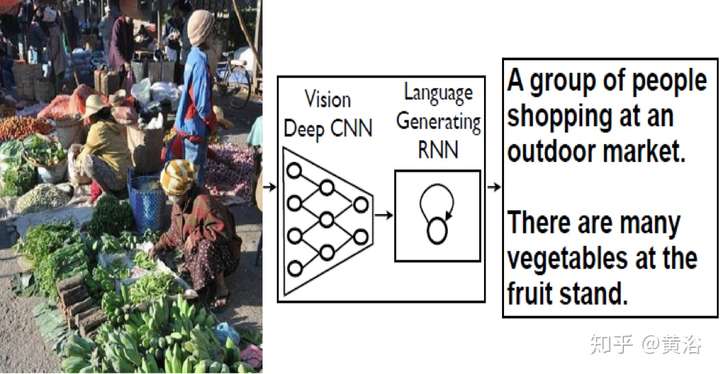
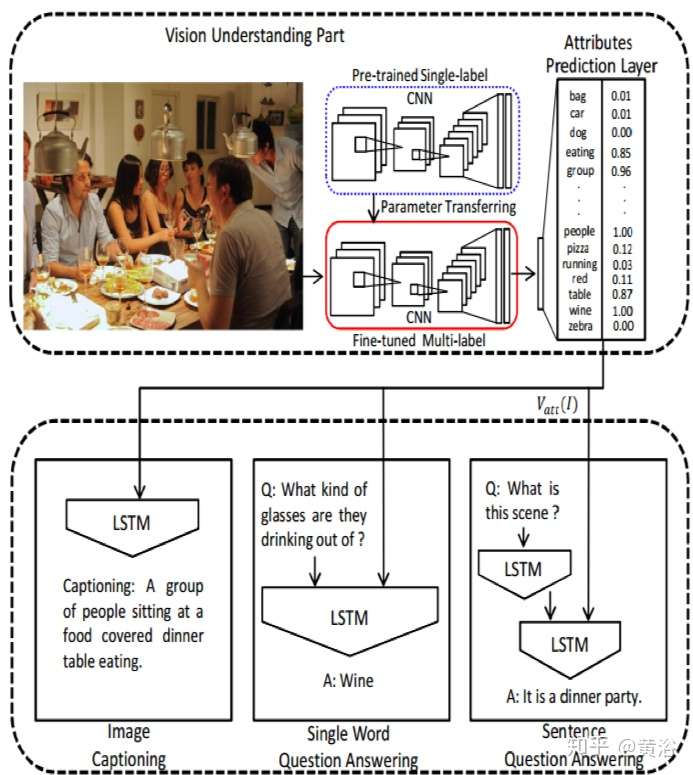
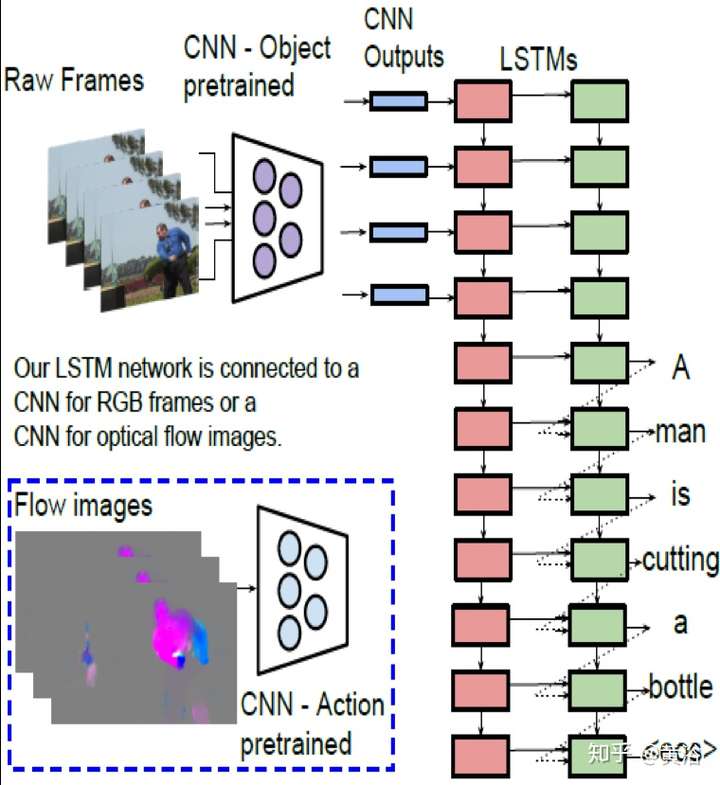
4 內容問答(Q&A)。
Q&A 也是計算機視覺和NLP的結合,其實質是在圖像描述和語言描述之間建立一個橋梁。有人說,Q&A是一個Turing Test的好問題,這里深度學習就是在幫助理解圖像的描述,問題的組成,以及它們模式之間的交互。
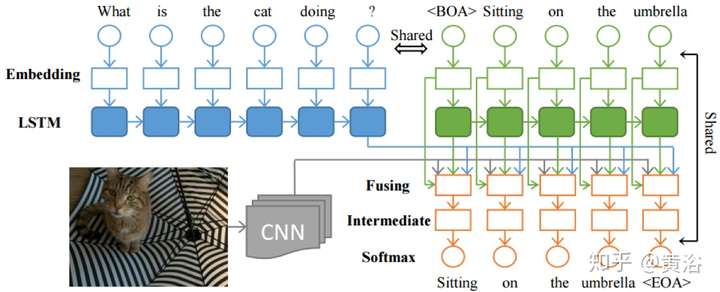
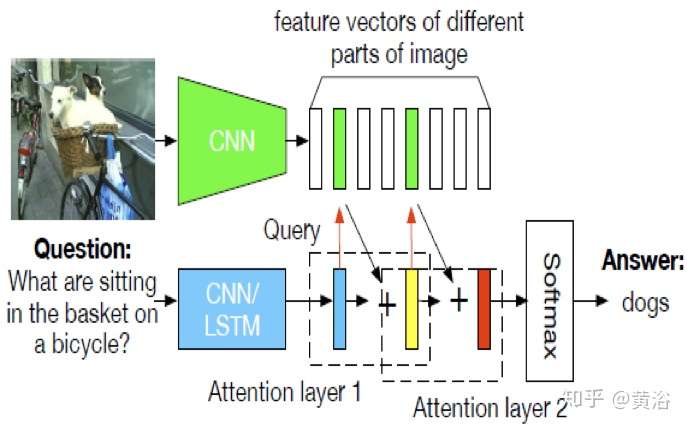
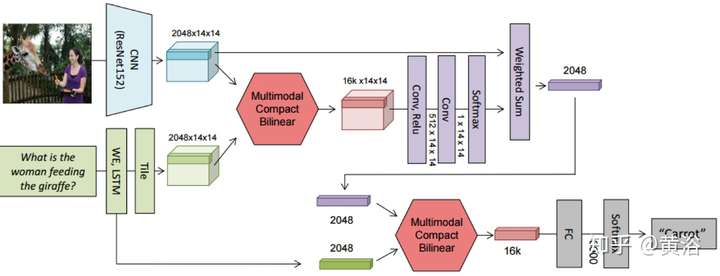
有些CNN的應用還是需要進一步改進模型,性能并沒有達到滿意。不過,大家高興地看到深度學習已經進來了,以后隨著研究的深入性能會越來越好。